The book; 'Smarter: The New Science of Building Brain Power' by Dan Hurley refers to 20 minutes daily of N-back training increases fluid intelligence. So go ask your doctor how to perform that training and what testing is needed to see that you increased your fluid intelligence. Your doctor knows nothing about this; you don't have a functioning stroke doctor.
RUN AWAY!
You have to somehow recover
your lost 5 years because of your stroke and I'm sure your doctor knows nothing on that.
Working memory training revisited: A multi-level meta-analysis of n-back training studies
Psychonomic Bulletin & Review volume 24, pages 1077–1096 (2017)
Abstract
The efficacy of working memory (WM) training has been a controversial and hotly debated issue during the past years. Despite a large number of training studies and several meta-analyses, the matter has not yet been solved. We conducted a multi-level meta-analysis on the cognitive transfer effects in healthy adults who have been administered WM updating training with n-back tasks, the most common experimental WM training paradigm. Thanks to this methodological approach that has not been employed in previous meta-analyses in this field, we were able to include effect sizes from all relevant tasks used in the original studies. Altogether 203 effect sizes were derived from 33 published, randomized, controlled trials. In contrast to earlier meta-analyses, we separated task-specific transfer (here untrained n-back tasks) from other WM transfer tasks. Two additional cognitive domains of transfer that we analyzed consisted of fluid intelligence (Gf) and cognitive control tasks. A medium-sized transfer effect was observed to untrained n-back tasks. For other WM tasks, Gf, and cognitive control, the effect sizes were of similar size and very small. Moderator analyses showed no effects of age, training dose, training type (single vs. dual), or WM and Gf transfer task contents (verbal vs. visuospatial). We conclude that a substantial part of transfer following WM training with the n-back task is task-specific and discuss the implications of the results to WM training research.
Working memory (WM) training has stirred considerable interest amongst researchers and public at large during the past decade (von Bastian & Oberauer, 2014; Green & Bavelier, 2008; Klingberg, 2010; Lövdén, Bäckman, Lindenberger, Schaefer, & Schmiedek, 2010; Morrison & Chein, 2011). The main reason for this widespread interest is that WM has been linked to a number of important skills, such as academic achievement and general intellectual capacity (Engle, 2002; Shipstead, Redick, & Engle, 2010). Moreover, WM deficits often occur in common clinical conditions, such as dyslexia, ADHD, and major depression, as well as in normal aging (Lezak, Howieson, & Loring, 2004). As a system for short-term maintenance and manipulation of task-relevant information (Baddeley, 2000), WM is inherently involved in all higher-level cognitive activities. Accordingly, WM training, if successful, might have wide-reaching consequences for an individual.
The results from the initial WM training studies were very promising, because they suggested that it is possible to improve performance not only on the trained task but also on untrained tasks measuring other cognitive functions (Jaeggi, Buschkuehl, Jonides, & Perrig, 2008; Klingberg, Forssberg, & Westerberg, 2002). The initial enthusiasm, however, turned into a controversy as subsequent training studies reported mixed results (Brehmer, Westerberg, Bäckman, 2012; Bürki, Ludwig, Chicherio, & De Ribaupierre, 2014; Bäckman et al., 2011; Chooi & Thompson, 2012; Colom et al., 2013; Dahlin, Neely, Larsson, Bäckman, & Nyberg, 2008; Jaeggi et al., 2008, 2010; Klingberg et al., 2002, 2005; Kundu, Sutterer, Emrich, & Postle, 2013; Lilienthal, Tamez, Shelton, Myerson, & Hale, 2013; Oelhafen et al., 2013; Redick et al., 2013; Salminen, Strobach, & Schubert, 2012; Thompson et al., 2013; Waris, Soveri, & Laine, 2015). The key issue is the existence of generalization following cognitive training, because the goal is to elicit positive transfer effects on untrained tasks. Most training studies make a distinction between near and far transfer effects. Near transfer refers to enhanced performance in a task that is intended to measure the trained cognitive domain and far transfer to improvement in another cognitive domain, such as WM training leading to better performance in a task measuring intelligence (von Bastian & Oberauer, 2014). Because WM training studies have reported near transfer, far transfer, both near and far transfer, or no transfer at all, it has been difficult to draw conclusions about the efficacy of WM training. What complicates the matter further is that many of the previous training studies have suffered from methodological shortcomings, such as using small sample sizes, employing a no-contact control group, failing to randomly assign participants to groups, or using only a single task to measure a given cognitive ability (Melby-Lervåg & Hulme, 2013; Melby-Lervåg, Redick, & Hulme, 2016; Morrison & Chein, 2011; Shipstead, Redick et al., 2010; Shipstead, Redick, & Engle, 2012).
Previous meta-analyses on working memory training
Given the widespread interest in WM training and the large variability in results, it is not surprising that during the past five years a number of meta-analyses have addressed the outcomes of WM training (Au et al., 2015; Dougherty, Hamovitz, & Tidwell, 2016; Melby-Lervåg, & Hulme, 2013; Melby-Lervåg & Hulme, 2016; Melby-Lervåg et al., 2016; Schwaighofer, Fischer, & Bühner, 2015; Weicker, Villringer, & Thöne-Otto, 2016; for meta-analyses investigating not only WM training, see Hindin & Zelinski, 2012; Karbach, & Verhaeghen, 2014; Karr, Areshenkoff, Rast, & Garcia-Barrera, 2014; Kelly et al., 2014). Near and far transfer effects of different kinds of WM training have been studied in four meta-analyses (Melby-Lervåg & Hulme, 2013; Melby-Lervåg et al., 2016; Schwaighofer et al., 2015; Weicker et al., 2016). The results from these meta-analyses (Table 1) with both clinical and healthy samples of children and adults showed that WM training can produce small to large short-term near transfer effects (verbal and visuospatial WM tasks) and null to small effects of transfer to verbal and visuospatial reasoning (or fluid intelligence; Gf) tasks. The results also showed small transfer effects to cognitive control (Melby-Lervåg & Hulme, 2013; Weicker et al., 2016) and attention (Weicker et al., 2016), but no transfer to long-term memory (Weicker et al., 2016), arithmetic skills (Melby-Lervåg & Hulme, 2013; Schwaighofer et al., 2015; Melby-Lervåg et al., 2016), reading comprehension (Melby-Lervåg et al., 2016), or word decoding (Melby-Lervåg & Hulme, 2013; Schwaighofer et al., 2015; Melby-Lervåg et al., 2016).
As is evident from the short review above, there is some disagreement between the previous meta-analyses, particularly regarding the size of the near transfer effects. These discrepancies are at least partly due to differences in decisions regarding the studies included in the meta-analyses and the categorization of tasks into different cognitive domains. For example, the meta-analysis by Melby-Lervåg et al. (2016) included studies that were not randomized, controlled trials. Furthermore, all previous meta-analyses included only one measure per domain per study. In some cases, this measure was a single task selected to represent a domain in a study, whereas in others, a mean value across the tasks was used. Moreover, the choice of which tasks to include varies between the meta-analyses. For example, unlike the other meta-analyses, Schwaighofer et al. (2015) did not include the n-back task in the near transfer measures due to validity issues with this task. Also, simple span tasks, such as the digit span, were considered WM measures in the Melby-Lervåg and Hulme (2013) study, whereas the other meta-analyses coded simple spans as measures of short-term memory (STM; Schwaighofer et al., 2015; Weicker et al., 2016) or excluded them completely from the analyses (Melby-Lervåg et al., 2016). Finally, a close look at the measures in Melby-Lervåg and Hulme (2013) showed three instances where the trained task itself was included in the near transfer analyses, likely leading to an undue inflation of the corresponding effect size. Of the previous meta-analyses, Melby-Lervåg and Hulme (2013) reported the strongest effect sizes for near transfer. Given these issues concerning the previous meta-analyses, further meta-analyses in this popular research field are warranted.
Background for the present study
The variety of WM training programs, experimental designs, and participant groups makes it challenging to draw definite conclusions on the WM training outcomes. To limit three sources of variability (training program, age, health status), the present meta-analysis focused solely on studies with healthy adults who trained with the most commonly used computerized experimental WM training paradigm, namely with n-back tasks. In the n-back task (Kirchner, 1958), the participant is presented with a sequence of stimuli and the task is to decide for each stimulus whether it is the same as the one presented n trials earlier. In a single n-back task, the participant is required to attend to one stream of stimuli, and in a dual n-back task, two streams of stimuli are presented simultaneously. Figure 1 shows an example of a dual n-back task with an auditory-verbal and a visuospatial stream of stimuli. Previous studies comparing the effects of single and dual n-back training have shown that both task versions seem to be equally effective in producing generalization and that the transfer effects are fairly similar (Jaeggi et al., 2010; Jaeggi, Buschkuehl, Shah, & Jonides, 2014). The n-back task often is highlighted as a WM updating measure (Szmalec, Verbruggen, Vandierendonck, & Kemps, 2011), but it also reflects active maintenance and capacity of the WM (plus interference control if so-called lure stimuli are included in the stimulus sequence; see NIMH Research Domain Criteria Workshop on Working Memory, 2010). The concurrent validity of the n-back task, however, has been questioned as previous studies have reported low correlations between the n-back task and other WM tasks, especially complex span tasks (Miller, Price, Okun, Montijo, & Bowers, 2009; see Redick & Lindsey, 2013, for a meta-analysis). Nevertheless, a recent study showed that at a latent level, the n-back task is highly correlated with other WM tasks (complex spans, WM updating tasks, and sorting spans; Schmiedek, Lövdén, & Lindenberger, 2014).
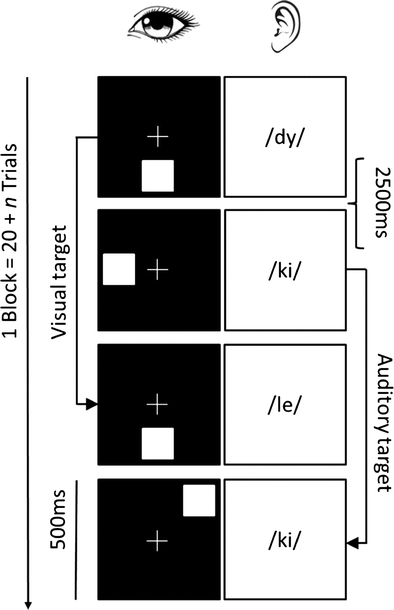
Depiction of the dual n-back task. In a 2-back version, the participants should press the corresponding “yes” button for the third location and for the fourth syllable.
The efficacy of n-back training has previously been investigated in three recent meta-analyses (Au et al., 2015; Melby-Lervåg & Hulme, 2016; Melby-Lervåg et al., 2016). Au et al. (2015) focused solely on the training effects on Gf. They included 20 studies with healthy adults in their analyses and found a small transfer effect of n-back training to Gf (g = 0.24). Au et al. (2015) also investigated the effects of various moderators, such as the type of control group (active or passive), type of n-back task (single or dual), and type of material in the Gf transfer tasks (matrix or nonmatrix; verbal or visuospatial). Active control groups typically receive the same amount of training as the training groups do, but with tasks that are not intended to tap WM to any greater extent. Passive control groups only participate in pre- and postsessions. The results from the Au et al. (2015) meta-analysis indicated that studies with passive control groups showed more transfer to Gf than studies with active control groups. However, their follow-up analyses revealed that this finding did not stem from a difference between active and passive control groups but from the training groups for some reason performing better in studies with passive controls than in studies with active controls. According to Au et al. (2015), these results do not support the idea that the Hawthorne or expectancy effects affect the results. Finally, their results showed no effects of the other aforementioned moderators. The Au et al. (2015) meta-analysis was challenged by Melby-Lervåg and Hulme (2016) who criticized the exclusion of relevant studies, the calculation of effect sizes without taking pretest differences between groups into account, and the interpretation of the results comparing active and passive control groups. Melby-Lervåg and Hulme (2016) argued that even though the difference between active and passive control groups was not statistically significant in the Au et al. (2015) meta-analysis, there was a difference in the pre-post effect sizes between those two groups. They also emphasized that the analysis only consisted of 12 studies in each category. Melby-Lervåg and Hulme (2016) reanalyzed the Au et al. (2015) data by including only the nonverbal reasoning tasks and correcting for possible pretest differences between groups. They found a very small but statistically significant effect of transfer to these tasks (g = 0.13). Au et al. (2016) have later responded to this critique, and they maintain that the discrepancy between the effect sizes in the Au et al. (2015) and Melby-Lervåg and Hulme (2016) analyses is mainly related to differences in the various meta-analytic decisions, such as the fact that Melby-Lervåg and Hulme (2016) compared the same treatment group to several control groups without taking the dependency between these comparisons into account. Furthermore, to avoid confounds stemming from methodological differences between studies, Au et al. (2016) compared active control groups to passive control groups within such n-back training studies that had employed both. The results from those analyses showed no difference between the two types of control groups.
In their recent meta-analysis on different kinds of WM training, Melby-Lervåg et al. (2016) included the type of training paradigm as a moderator in their analyses. These results showed null to moderate training effects from n-back training to untrained WM tasks (verbal WM: g = 0.17 for studies with active controls and g = 0.12 for passive controls; visuospatial WM: g = 0.24 with active controls and g = 0.52 with passive controls) and very small but statistically significant transfer effects to nonverbal problem solving (g = 0.15 with active controls and g = 0.26 with passive controls). Melby-Lervåg et al. (2016) further pointed out that those n-back training studies with active control groups that showed the largest transfer effects to nonverbal ability all had small sample sizes (less than 20 participants per group) and most of them also showed decreases in performance from pretest to posttest in the control groups. Melby-Lervåg et al. (2016) emphasized that only studies with active control groups can be used to evaluate the effectiveness of an intervention and they “recommend that investigators stop conducting working memory training studies with untreated control groups and that journals stop publishing them” (p. 524).
Compared with the earlier meta-analyses on transfer following n-back training, the present one has several distinctive features that we deem as important. First, as mentioned, limiting the sources of variability (here training method, age, and health status) should yield results that are easier to interpret. Second, we strictly separated the trained tasks from the untrained ones as mixing these would risk inflating the near transfer effect (see above for the discussion on the meta-analysis by Melby-Lervåg & Hulme, 2013). Third, meta-analytic near transfer measures have lumped together untrained WM tasks that differ from the training tasks only by their stimuli and WM tasks that are structurally different from the training tasks (Melby-Lervåg & Hulme, 2013; Melby-Lervåg et al., 2016; Schwaighofer et al., 2015; Weicker et al., 2016). We believe that one should keep these two transfer measures apart to obtain a more detailed view on the generalizability of WM training. For example, in n-back training studies a near transfer effect rising only from untrained n-back tasks could speak for acquisition of task-specific strategies rather than improved WM per se. Fourth, all previous meta-analyses have included only one measure (one task or average of several tasks) per domain per original sample in the analyses. The rationale for choosing a specific task to represent a certain domain is not always fully explicated. For example, in the meta-analysis by Melby-Lervåg and Hulme (2013), there seems to be some inconsistency in the selection of tasks so that a specific task is excluded for some studies but not for all. In the present meta-analysis, we were able to include all measures from the original studies by employing a multilevel meta-analytical approach, and thereby having less risk of biasing the estimated training effect.
More at link.
No comments:
Post a Comment