So you agree that nobody knows anything about getting survivors recovered. But you do nothing to improve that failure. No clue what any of this means.
Interaction of network and rehabilitation therapy parameters in defining recovery after stroke in a Bilateral Neural Network
Journal of NeuroEngineering and Rehabilitation volume 19, Article number: 142 (2022)
Abstract
Background
Restoring movement after hemiparesis caused by stroke is an ongoing challenge in the field of rehabilitation. With several therapies in use, there is no definitive prescription that optimally maps parameters of rehabilitation with patient condition. Recovery gets further complicated once patients enter chronic phase. In this paper, we propose a rehabilitation framework based on computational modeling, capable of mapping patient characteristics to parameters of rehabilitation therapy.
Method
To build such a system, we used a simple convolutional neural network capable of performing bilateral reaching movements in 3D space using stereovision. The network was designed to have bilateral symmetry to reflect the bilaterality of the cerebral hemispheres with the two halves joined by cross-connections. This network was then modified according to 3 chosen patient characteristics—lesion size, stage of recovery (acute or chronic) and structural integrity of cross-connections (analogous to Corpus Callosum). Similarly, 3 parameters were used to define rehabilitation paradigms—movement complexity (Exploratory vs Stereotypic), hand selection mode (move only affected arm, CIMT vs move both arms, BMT), and extent of plasticity (local vs global). For each stroke condition, performance under each setting of the rehabilitation parameters was measured and results were analyzed to find the corresponding optimal rehabilitation protocol.
Results
Upon analysis, we found that regardless of patient characteristics network showed better recovery when high complexity movements were used and no significant difference was found between the two hand selection modes. Contrary to these two parameters, optimal extent of plasticity was influenced by patient characteristics. For acute stroke, global plasticity is preferred only for larger lesions. However, for chronic, plasticity varies with structural integrity of cross-connections. Under high integrity, chronic prefers global plasticity regardless of lesion size, but with low integrity local plasticity is preferred.
Conclusion
Clinically translating the results obtained, optimal recovery may be observed when paretic arm explores the available workspace irrespective of the hand selection mode adopted. However, the extent of plasticity to be used depends on characteristics of the patient mainly stage of stroke and structural integrity. By using systems as developed in this study and modifying rehabilitation paradigms accordingly it is expected post-stroke recovery can be maximized.
Background
Stroke is the second most leading cause of death globally [1] while leaving 50% of the survivors disabled for life [2]. It is caused as a result of loss of blood supply to a part of the brain either due to ischemia (block in a cerebral blood vessel due to a clot) or hemorrhage (rupture of the blood vessel) leading to a lesion. The most common disability after stroke is weakness in the upper limb [3] contralateral to the damaged hemisphere resulting in a condition known as hemiparesis [4].Since the upper limb is compromised, the quality of life after stroke is severely affected [5] and the subjects become dependent on caregivers for their day-to-day lives [6]. In order to restore the lost functionality, physiotherapists often administer physical therapy as a rehabilitative strategy to patients [7].Rehabilitative therapy is of different kinds, depending on the type of setting and movements used (for a detailed review, please see [8]). For example, Constraint-Induced Movement Therapy [9] (CIMT) advocates moving only the affected arm while restraining the intact arm to accomplish various tasks that one might encounter in daily life. This therapy was developed in order to encourage spontaneous use of the affected arm and overcome learned non-use. In contrast, Bimanual Therapy [10] (BMT) endorses moving both arms simultaneously to specific targets placed in the workspace. This therapy was developed in order to provide training for tasks that require bimanual movements, since many tasks in daily life require coordination between the two arms. As can be seen from the definitions, the two therapies given here are apparently contradictory to each other as one views the healthy arm to be opposing the paretic arm while the other views it as being assistive. However, these therapies can be grouped together broadly as task-oriented rehabilitation [11] as they are administered as tasks to be completed by the patients. In such therapies, patients are often advised to keep practicing the task until they are perfected.
Though task-oriented rehabilitation has been around for long, recently, doubts have been raised about its actual efficacy. When using task-oriented rehabilitation practices, it is found that patients are able to perform well only if the testing conditions are identical to the training conditions indicating that it leads to poor retention [12] and less generalization [13]. On the contrary, introducing variability in practice has been shown to increase retention and transfer of skill to other unlearned tasks [14]. Additionally, a new task paradigm devised by Krakauer and Cortés [15] has proposed that encouraging patients to make self-chosen movements in a rich environment can lead to higher recovery levels compared with dull, repetitive task-oriented practice. Further, since the movements are self-chosen, the entire movement/action space is available for the patients to explore and are not restricted by the constraints dictated by a task. Hence, the complexity of the movement is higher under such a paradigm compared to task-oriented rehabilitation. (However, it should be noted that this paradigm was tested on a subset of patients with subacute stroke, with whom it has not yielded encouraging results [16]. Therefore, this technique still needs more vigorous testing, with multiple patient groups, before being accepted as a mainstream rehabilitation technique). Thus, there are several parameters that need to be considered while choosing a rehabilitation paradigm.
In this study, we wanted to develop a computational model capable of understanding the effect of these parameters on recovery after stroke and how they need to be modified under different patient characteristics. We chose reaching as the patient behaviour to replicate with the model. Stroke was then induced in the model, and recovery patterns were observed. Several computational models implement a similar process of capturing the reaching behaviour of humans (for an extensive review, see [17]). One approach taken by these models is to replicate the brain's sensory-motor loop [18,19,20]. The movement performed is captured by the sensory module and fed back to the motor module, which uses it to compare the difference between intended action and performed action similar to the brain. The model then tries to reduce the error between the intended and actual movements. Models can also be developed for specific rehabilitation therapy to understand its effect on recovery [21]. However, since these models have separate modules dedicated for each brain area, as the complexity of the movement increases, the model's computational cost also increases while still being designed only to address a specific task or a class of tasks or implement a particular therapy. There are also several predictive models that use patient data (lesion size, location, time from onset, initial impairment, etc.) to predict recovery over a time frame [22, 23]. But such models usually only explain recovery in a particular group of patients while classifying the rest as outliers incapable of complete recovery.
For the current study, we wanted to replicate the reaching behaviour observed in stroke patients. Though other models have attempted to do this, they all face the same issue of being very restricted in use only with specific therapies or specific patient data. The aim of our study was to develop a model that can be used with multiple therapies in order to allow a comparison between them to find the optimal therapy for a given set of patient characteristics.
Recently several studies have shown the similarity in activity between the different convolutional layers of the convolutional neural networks (CNNs) and sensory systems in the brain—both visual [24] and auditory cortex [25]. Additionally, these studies have also shown that optimizing the network architecture for a given task, results in connectivity similar to that observed in the brain [25]. Taking this as inspiration, we used convolutional layers on the input side of the network to model the visual side of the visuomotor pathway. The output side of the network consists of a multilayer perceptron, with a single hidden layer, whose output is the muscle activations required to reach a given target in 3D space. The network is trained as a whole with the input being an image consisting of a sphere representing the target position in 3D space while the output is the muscle activations required by the arm to reach the target. The network is organised as a bilateral architecture to resemble the bilateral organisation of the brain. Similar to the two hemispheres of the brain, the CNN is divided into two halves, where the output from each half controls the movement of the respective arm. For easy depiction, we assume that each half of the network controls the corresponding ipsilateral arm, instead of the more realistic contralateral arm. By inducing stroke in one of the halves, we were able to selectively impair the corresponding arm resulting in hemiparesis. To this model of hemiparesis, rehabilitation therapies of different kinds were then administered to and the performance after each was measured and compared. By this comparison, we were able to identify optimal rehabilitation protocol for each condition of stroke. However, it is to be noted that with the current network, we try to map the behaviour of the network to the behaviour seen in stroke patients, in particular their reaching behaviour. Thus, with the current model we are not trying to replicate the neural activity pattern of every layer independently in the cortex, but only model a gross similarity with the visuomotor pathway of the brain, with the lower layers of the network representing the visual areas and the higher layers, the motor areas. Further, in order to reduce the model complexity, we have greatly simplified the working of both the visual and motor areas to only those required for the task at hand.
Methods
Arm model
A two-link arm model is used with three degrees of freedom: (i) elbow flexion, (ii) shoulder flexion, and (iii) shoulder rotation and is hence capable of moving in a 3D workspace. Each degree of freedom is controlled by an agonist–antagonist muscle pair with each arm controlled by 6 muscles in total (schematic shown in Fig. 1). The network controls two such arms—right and left. The output of the network is the 12 muscle activations required for the arms to reach a visually presented target in the 3D-workspace. The origin of the workspace is considered to be in the hollow of the neck, between the clavicle bones of the shoulder. The right shoulder is at coordinates [0.15,0,0] and the left shoulder is at coordinates [− 0.15,0,0]. The muscle activations obtained at the output of the network are used to calculate the elbow and shoulder angles, which is then used to find the position of the end effector. This position is then compared with the actual target position given as input to the network (described in the next section). The error between these two values is then backpropagated through the network, and the weights of the network are modified accordingly.
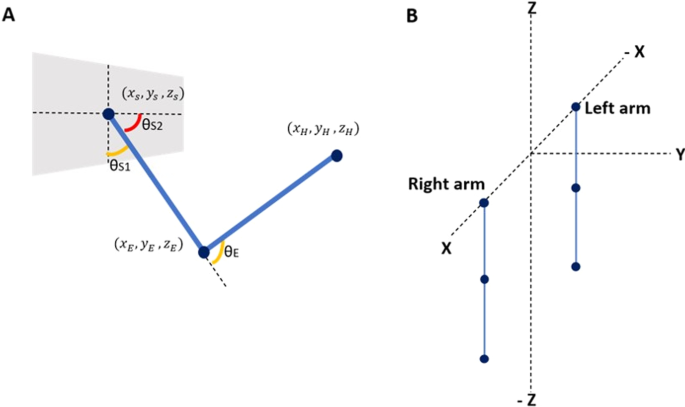
A A two link arm model with 2DoFs at the shoulder and 1DoF at the elbow. B The configuration of the two arms at initial instant before performing rotations
Angles from the corresponding muscle activations are calculated as follows,
where,
is the muscle activation input to the agonist muscle andis the muscle activation to the antagonist muscle.
The above rotation matrices are used to calculate the position of the end effector along with the angles calculate above, as follows,
where,
, and are the starting coordinates of the hand ([0.15, 0, 0.6] for right and [− 0.15, 0, 0.6] for left (0.6 is the assumed length of the whole arm)), elbow ([0.15, 0, 0.3] for right and [− 0.15, 0, 0.3] for left (0.3 is the assumed length of the upper arm)) and shoulder ([0.15, 0, 0] for right and [− 0.15, 0, 0] for left) respectively. We assumed the arm length to be 0.6 units. The length from the shoulder to elbow and elbow to wrist were assumed to be equal (0.3 units each) to make the computation simpler. We also assumed the shoulder length to be 0.3. The origin is supposed to be centered at the forehead, and hence the left shoulder’s x-coordinate was at − 0.15 while the right was at + 0.15.
No comments:
Post a Comment